Snowboards and Sequencers

There's an interesting concept in snowboards: Each board has a rating of flexibility, which measures how easily that board can bend.
For a beginner snowboarder, it is important that the board is on the softer side. There's multiple reasons for this, but primarily it is because boards that bend with more ease are more forgiving, permitting easier turns and navigation in particular when going slow, as novices tend to. In contrast, for a person with advanced skills, flexible snowboards may get in the way of playful riding, because they are not that easy to ride at higher speeds or on icy conditions. When going fast, a flexible board may be less predictable and it might flutter. Advanced snowboarders prefer stiffer boards.
Different boards for different needs.
Sequencers, a.k.a. Consensus Engines
We can use a similar kind of flexibility rating for consensus engines. Some are more appropriate for beginner use-cases. Others fit better when the use-cases are more advanced.
What does a beginner use-case look like for a consensus engine? What would the builder team care about?
- Not much need for customization or pushing the limits of the engine. Whether that is in terms of tps (transactions per second), finalization latency (blocks per second), throughput (megabytes per second), scalability (evolution of performance as # of validators increases).
- Requires several features that just work within some default parameters. There is need for an RPC entry point to query the state. There should be support to handle application state synchronization. Among the most important ones is probably event and block indexing as well.
- Intuitively, the consensus engine is not part of the core value proposition of the product that the team is building or maintaining. It is unlikely that the engine contributes a key feature to differentiate the business. We can see this clearly in the fact that there are teams in the decentralization industry who are launching products that are centralized, and that does not correlate with their success.
- The team runs the consensus engine as a standard technology, it's plugged-into the stack and then developers forget about it for months on end. In extreme cases, the team may even avoid upgrading it for years.
What about the advanced use-case? This is where it gets interesting. Some of these ideas may seem debatable at first glance, but this is by definition what it means for a use-case to be advanced from what I have noticed in the last few years:
- The team likely has a custom fork of the consensus engine.
- There is likely a senior engineer in the organization that understands the consensus engine very well. The engineer regularly talks to the team maintaining the upstream version (vanilla) engine. The core maintainers of the engine may actively contribute to maintaining this fork. It happened multiple times that Informal Systems, the maintainers of CometBFT, contributed or gave feedback on forks of CometBFT.
- The existence of a certain component (or feature) of the engine is considered a security liability or a performance hindrance, and therefore this team disables discourages the use of that feature in their deployment. For instance, signing using a local key; a particular storage backed is a no-no; particular flags are mandatory when booting up the system; specific configuration parameters like timeouts or p2p knobs are adjusted to run a node consistently with the rest of the network.
- Corollary to the above: It is rare that a node in the network runs an indexer alongside consensus. The consensus engine creates blocks and then writes them to cold storage (put simply), and that's OK because the company has 1 team dedicated to operating a separate indexing sub-system that is specialized for hot access paths, using off-the-shelf web2 tools.
- The system might run at a lower latency than within tested ranges. The network topology is carefully orchestrated and monitored. Operators of nodes that are outliers in latency are advised to re-deploy, move, or upgrade their hardware to avoid impacting the tail latency.
The above points of distinction help to describe the product strategy for Malachite versus that of CometBFT.
Malachite and CometBFT
CometBFT is like the soft snowboard. It is forgiving. It has plenty of batteries included. Compared to other BFT engines, it benefits from the largest mindshare of engineers. It also has the cheapest onboarding and operating costs, at least in the short term. The codebase is the richest (over ten years) in the amount of corner-cases, features, as well as bugs and unusual conditions it can withstand. The code in CometBFT is wise from old age, if you will, and highly tolerant of mistakes. Like any other software, there are pitfalls and footguns, but fewer than the average.
Malachite is like the stiffer snowboard. It supports – and assumes – that the team using it have more specialized and advanced needs. Malachite is for the advanced usage, for those that are willing to go at break-neck speed out into the wild territories outside of the resorts. We started Malachite to build a decentralized sequencer for the Starknet L2 ecosystem, which is a use-cases with a lot more ambiguity and evolving needs; unlike CometBFT use-cases which are very well understood today.
In visual terms, this is how I would picture it.
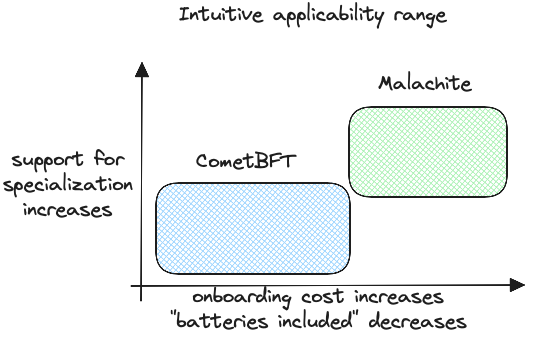
The analogy snowboards <> sequencer software starts to break down as we go into specifics. Namely, Malachite is the flexible software for advanced users, but advanced snowboarders require a stiffer – not a more flexible – board. Still, I found the analogy unusually insightful.
What do both cases have in common?
Two concerns that are relevant for both for the beginner and advanced use-cases are resilience and security. These are non-negotiable. Most software is like this, and this is doubly so for consensus systems. The system should be able to withstand moderate-to-severe denial of service attacks. Block production should function as long as a proportion of 2f+1 (out of 3f+1) of validators (replicas) can exchange messages within some latency envelope. It is fine to sacrifice liveness for safety if the algorithm is deterministic; this also makes it easier to reason about dependent systems (indexers, wallets, interoperability with other networks).
Is the tradeoff tight?
So far, I assumed that there must be a tradeoff between flexibility and onboarding costs. Malachite has superior support for specialization, i.e., flexibility and customization – it is a library in fact. Hence, it will take more time to onboard. CometBFT is easier to just roll out the door.
But is this a tight tradeoff? In snowboards, the tradeoff is hard. You pick a snowboard that has a certain flexibility rating on a spectrum, and then you're stuck with that board on the slopes until you switch to a different one. There's no button to tune the stiffness.
Physical reality has limits that way. Software is more lenient, however: We can make Malachite into a consensus library that offers both a delightfully simple onboarding experience as well as the most flexible consensus library possible.
So I would adjust the two dimensional space to distinguish between the current version of Malachite, let's call that v0, and the broader Malachite product as it evolves in time and is not confined to what the initial release comprises.
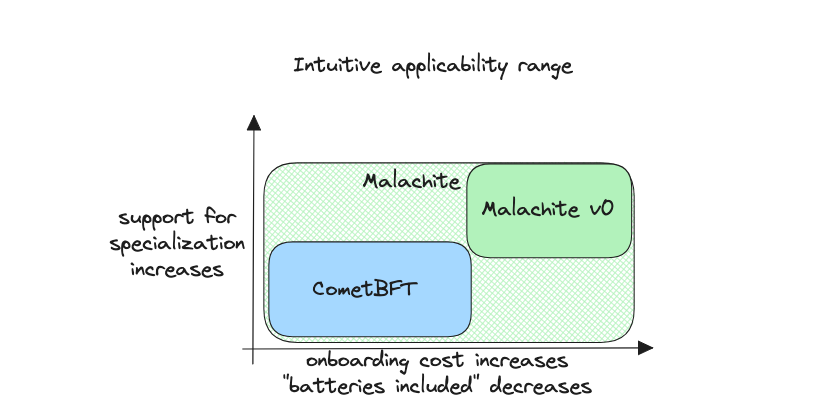
This is the plan with Malachite: We started simple, with the general purpose core that is the most critical part, which is just as predictable, safe, and battle-tested as CometBFT – except Malachite is a library and so the surface area that developers needs to deal with is wider, which in turns means a longer onboarding experience. This is just v0. The supple core. We then construct on top of that core supporting layers, to reduce developer and onboarding time. These supporting layers consist of higher level APIs – like Comet has ABCI, – simpler primitives, shim layers for quicker integration into various frameworks, extensions that make it easy to use or experiment, plug-ins that function like "batteries," such as indexers, RPC, a high performance mempool, and so on. All of these are optional, so that developers can re-imagine to tailor to their needs.
The ideas for supporting layers are not coming from our imagination. They are inspired from many cumulative years of designing consensus systems and maintaining them in practice. Even more important, they are inspired from what builders currently need, as we iterate and discover new use-cases and areas of applicability for consensus libraries. It used to be the case that only Layer 1s (full-fledged blockchains) require a BFT consensus engine, but today builders are a lot more ambitious and competent in building decentralized systems, we understand such systems much better as an industry, so the use-cases for Malachite are a lot more surprising. For this reason, Malachite is intended to decentralize whatever.
Two remarks. I did less editing than usual and was more spontaneous with writing this post, which may explain more typos or murkiness in ideas. Like all other posts, what I express here is purely personal thoughts; though I use "we" in writing, I do that because I prefer to write that way, not because I represent my team or company.



Comments ()